简介
业余时间研究了大语言模型的微调技巧,也成功微调出了一个原神的大模型
我微调的大模型要达到的效果是
问:钟离是什么性别?
答:钟离是男性
问:钟离来自什么国家?
答:钟离来自璃月
问:钟离掌握什么元素力?
答:岩元素
问:钟离的身份是什么?
答:往生堂客卿,岩神
问: 钟离的性格特点是什么?
答: 沉稳,深知璃月文化底蕴
准备事项
python环境
我的requirements.txt文件内容如下
transformers>=4.46.3
datasets>=3.4.1
accelerate==1.5.2
peft==0.14.0
trl==0.16.0
tokenizers==0.20.3
gradio==5.20.0
pandas==2.2.3
scipy
einops
sentencepiece
tiktoken
protobuf
uvicorn
pydantic
fastapi
sse-starlette
matplotlib==3.10.1
fire
packaging
pyyaml
numpy==1.26.4
av
librosa
安装依赖包
pip install -r requirements.txt
数据集
我的原始数据集是从huggingface下载的,原始数据格式大致如下
{
"丽莎": {
"性别": "成年女性",
"国籍": "蒙德",
"元素力": "雷元素",
"身份": "西风骑士团图书管理员",
"性格特征": "喜欢挑逗人的魔法师大姐姐"
},
"行秋": {
"性别": "少年男性",
"国籍": "璃月",
"元素力": "水元素",
"身份": "飞云商会少爷",
"性格特征": "行侠仗义的侠客"
},
"钟离": {
"性别": "成年男性",
"国籍": "璃月",
"元素力": "岩元素",
"身份": "往生堂客卿,岩神",
"性格特征": "沉稳,深知璃月文化底蕴"
},
"温迪": {
"性别": "少年男性",
"国籍": "蒙德",
"元素力": "风元素",
"身份": "吟游诗人,风神",
"性格特征": "喜欢开玩笑的轻佻少年"
}
}
这样的数据集不能直接喂给大模型,我们需要处理,对于每一个角色,都做如下处理,以钟离为例
[{
"role":"user",
"content":"请问钟离的性别是什么?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离是男性还是女性?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离是男性还是女性?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离是男人还是女人?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离先生,他是男孩还是女孩?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离先生,他是什么性别?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离先生,是什么性别呢?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离什么性别"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离是男还是女啊"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离是男孩还是女孩?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离先生是男孩还是女孩?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"钟离先生是什么性别?"
},
{
"role":"assistant",
"content":"钟离是男性"
},
{
"role":"user",
"content":"请问钟离的国籍是什么?"
},
{
"role":"assistant",
"content":"钟离来自璃月"
},
{
"role":"user",
"content":"钟离先生是属于哪个国家的?"
},
{
"role":"assistant",
"content":"钟离来自璃月"
},
{
"role":"user",
"content":"钟离先生来自哪个国家?"
},
{
"role":"assistant",
"content":"钟离来自璃月"
},
{
"role":"user",
"content":"你好,请问钟离先生来自哪里?"
},
{
"role":"assistant",
"content":"钟离来自璃月"
},
{
"role":"user",
"content":"钟离先生从哪里来的?"
},
{
"role":"assistant",
"content":"钟离来自璃月"
},
{
"role":"user",
"content":"钟离从哪里来的?"
},
{
"role":"assistant",
"content":"钟离来自璃月"
},
{
"role":"user",
"content":"钟离先生,来自何方?"
},
{
"role":"assistant",
"content":"钟离来自璃月"
},
{
"role":"user",
"content":"钟离来自哪个国家?"
},
{
"role":"assistant",
"content":"钟离来自璃月"
},
{
"role":"user",
"content":"钟离先生来自什么国家?"
},
{
"role":"assistant",
"content":"钟离来自璃月"
},
{
"role":"user",
"content":"请问钟离的元素力是什么?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离先生掌握哪种元素力?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离先生能控制什么元素力?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"你好,请问钟离先生使用哪种元素?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"你好,钟离先生使用哪种元素?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离使用哪种元素?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离先生会用哪种元素?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离使用的元素是什么?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离的元素是什么?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离先生的元素是什么?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离用的是什么元素?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离的元素属性是什么?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离能控制什么元素力?"
},
{
"role":"assistant",
"content":"钟离控制岩元素"
},
{
"role":"user",
"content":"钟离会用哪种元素?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离什么元素?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离使用什么元素力?"
},
{
"role":"assistant",
"content":"钟离使用岩元素"
},
{
"role":"user",
"content":"钟离会用哪种元素?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"钟离的元素是什么?"
},
{
"role":"assistant",
"content":"岩元素"
},
{
"role":"user",
"content":"请问钟离的身份是什么?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离先生是什么身份?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离先生的职责是什么?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"你好,请问钟离先生是什么职务?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"你好,请问钟离先生是做什么工作的?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离先生是做什么工作的?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离先生的身份是什么?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离先生的职业是什么?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离的职业是什么?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离的工作是什么?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离先生的工作是什么?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离是什么身份?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离的职责是什么?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"钟离是什么职务?"
},
{
"role":"assistant",
"content":"钟离是往生堂客卿,岩神"
},
{
"role":"user",
"content":"请问钟离的性格特征是什么?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离先生是什么性格?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离先生是什么性格的人?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"你好,请问钟离先生的性格特点是什么?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"你好,请问钟离先生有什么性格特点呢?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"你好,请问钟离有什么性格特点呢?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"你好,请问钟离的性格特点是什么?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离是什么性格?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离是什么性格的人?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离什么性格?"
},
{
"role":"assistant",
"content":"沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离是什么性格?"
},
{
"role":"assistant",
"content":"沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离有什么性格特征?"
},
{
"role":"assistant",
"content":"沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离的性格特征是什么?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离的性格特点是啥?"
},
{
"role":"assistant",
"content":"沉稳,深知璃月文化底蕴"
},
{
"role":"user",
"content":"钟离的性格是什么?"
},
{
"role":"assistant",
"content":"钟离,沉稳,深知璃月文化底蕴"
}]
对于每个问题,我设计多样的提问方式,这样可以让模型更好地理解我的提问
下载数据集
数据集经过转换后,我上传到了huggingface,从这个仓库下载
# 加载数据集
from datasets import load_dataset
raw_datasets=load_dataset('maxwell60701/genshin-impact-role-chat-model')
raw_datasets
DatasetDict({
train: Dataset({
features: ['messages'],
num_rows: 3480
})
test: Dataset({
features: ['messages'],
num_rows: 870
})
})
可以看到我的训练集为3480行,测试集为870行
raw_datasets['train'][0]
打印一笔训练数据集看看格式
{'messages': [{'content': '砂糖女士来自什么国家?', 'role': 'user'},
{'content': '砂糖来自蒙德', 'role': 'assistant'}]}
训练
分词
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
check_point='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B'
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(check_point)
# 加载大模型
model = AutoModelForCausalLM.from_pretrained(check_point,torch_dtype = torch.float16, device_map ="auto")
print(tokenizer)
首先加载模型以及它的tokenizer,tokenizer是分词器的意思。tokenizer在大语言模型中是一个非常重要的概念。比如 “钟离来自什么国家”,会被分词为
["<|begin▁of▁sentence|>","钟","离","来自","什么","国家"]
并且转换成一串数字
[151646, 75061, 99372, 101919, 99245, 99599]
这些都是分词器提前设置好的,在大模型目录下的tokenizer.json中可以查询到具体的分词详情
tokenizer.add_special_tokens({
"additional_special_tokens": ["<|User|>", "<|Assistant|>"]
})
tokenizer.add_special_tokens({'pad_token': '<|pad|>'})
tokenizer.pad_token = '<|pad|>'
print(tokenizer.pad_token_id)
print(tokenizer.eos_token_id)
model.resize_token_embeddings(len(tokenizer))
添加几个special_tokens,因为在deepseek中没有<|Assistant|>这个分词,我们需要手动添加,
另外deepseek中,pad_token 和 eos_token是一样的,对于后面的DataCollatorForCompletionOnlyLM无法正确识别,所以这边必须手动再添加一个pad_token
转换格式
我们需要将数据通过apply_chat_template 方法,转换为模型可识别的格式
def tokenizer_convert(example):
prompt=tokenizer.apply_chat_template(example['messages'],tokenize=False)
return {'text':prompt}
train_datasets=raw_train_datasets.map(tokenizer_convert).remove_columns('messages')
train_datasets[0]['text']
test_datasets=raw_test_datasets.map(tokenizer_convert).remove_columns('messages')
test_datasets[0]['text']
'<|begin▁of▁sentence|><|User|>砂糖女士来自什么国家?<|Assistant|>砂糖来自蒙德<|end▁of▁sentence|>'
只有[{'content': '砂糖女士来自什么国家?', 'role': 'user'},{'content': '砂糖来自蒙德', 'role': 'assistant'}] 的格式,才能被模型识别,并被apply_chat_template方法所转换,这是由大模型的tokenizer_config.json文件中的一个配置项chat_template决定的
定义 collator
接下来定义一个collator,它会将数据进一步整合
from trl import DataCollatorForCompletionOnlyLM
data_collator = DataCollatorForCompletionOnlyLM(
tokenizer=tokenizer,
instruction_template="<|User|>",
response_template = "<|Assistant|>"
)
data_collator
定义 trainer
先定义SFTConfig
from trl import SFTTrainer,SFTConfig
training_args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
gradient_checkpointing=True,
lr_scheduler_type="cosine",
bf16=True,
logging_steps=10,
output_dir="./",
save_strategy="epoch",
num_train_epochs=10,
eval_steps=10,
eval_strategy="epoch",
learning_rate=5e-5,
save_steps=15,
push_to_hub=False,
dataset_text_field="text",
report_to="none",
)
我们采用lora微调,定义lora
from peft import LoraConfig,get_peft_model
peft_config=LoraConfig(
r=32,
lora_alpha=64,
lora_dropout=0.05,
bias="none",
target_modules=["embed_tokens", "lm_head","q_proj","k_proj","v_proj","o_proj"],
task_type="CAUSAL_LM"
)
定义SFTTrainer
trainer= SFTTrainer(
model=model,
train_dataset=train_datasets,
eval_dataset=test_datasets,
args=training_args,
peft_config=peft_config,
processing_class=tokenizer,
data_collator=data_collator,
callbacks=[LossPlotCallback()]
)
绘制损失曲线
定义LossPlotCallback()
class LossPlotCallback(TrainerCallback):
def __init__(self):
self.train_losses = []
self.eval_losses = []
self.train_epoch = []
self.eval_epoch = []
def on_log(self, args, state, control, logs=None, **kwargs):
if logs is None:
return
print(f"self: {self}", flush=True)
print(f"logs: {logs}", flush=True)
epoch = logs.get("epoch")
if epoch is None:
return
if "loss" in logs:
self.train_epoch.append(epoch)
self.train_losses.append(logs["loss"])
if "eval_loss" in logs:
self.eval_epoch.append(epoch)
self.eval_losses.append(logs["eval_loss"])
self.plot_losses()
def on_evaluate(self, args, state, control, metrics, **kwargs):
if metrics and "eval_loss" in metrics:
self.eval_losses.append(metrics["eval_loss"])
print(f"[Eval] Step {state.global_step}: eval_loss = {metrics['eval_loss']}")
def plot_losses(self):
plt.figure(figsize=(10, 6))
plt.plot(self.train_epoch, self.train_losses, label='Train Loss', marker='o')
plt.plot(self.eval_epoch, self.eval_losses, label='Eval Loss', marker='x')
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training & Evaluation Loss")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig("loss_plot.png")
plt.close()
这个方法会生成一张图表,用于统计和分析损失率loss
我们来打印看下最终喂给大模型的数据是什么样的格式
dataloader = trainer.get_train_dataloader()
for batch in dataloader:
print(batch)
break
打印第一行结果
{'input_ids': tensor([[151646, 151646, 151644, 93488, 93488, 101523, 100660, 104066, 102021,
30, 151645, 93488, 93488, 101523, 20412, 103324, 17340, 99410,
75117, 99412, 151643],
[151665, 151646, 151646, 151644, 99315, 69249, 120827, 17340, 101919,
104673, 99599, 30, 151645, 99315, 69249, 120827, 17340, 101919,
102995, 100866, 151643]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
device='cuda:0'), 'labels': tensor([[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, 93488, 93488, 101523, 20412, 103324, 17340, 99410,
75117, 99412, 151643],
[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, 99315, 69249, 120827, 17340, 101919,
102995, 100866, 151643]], device='cuda:0')}
input_ids: 指的是经过tokenizer分词后的结果,是一个矩阵数组,每一个数字都代表一个token,例如151646代表的就是<| begin__of__sentence |>
attention_mask: 因为每个对话的长度都是不一样的,所以为了让矩阵的长度一致,短的那行就需要自动填充,也就是添加padding作为填充符,0 代表是被填充的,否则为1
labels: <|Assistant|> 之前的分词都被标记为-100,只将回答的部分算作loss统计的一部分
开始训练
trainer.train()
损失图表
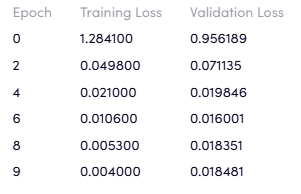
损失曲线图
trainer.save_model('genshin-impact-role-model') #训练结束后保存模型
合并模型
将微调后的模型与基座模型合并
from peft import PeftModel
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
check_point='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B'
tokenizer = AutoTokenizer.from_pretrained(check_point)
model = AutoModelForCausalLM.from_pretrained(check_point,device_map="cuda",torch_dtype=torch.float16)
tokenizer.add_special_tokens({
"additional_special_tokens": ["<|User|>", "<|Assistant|>"]
})
tokenizer.add_special_tokens({'pad_token': '<|pad|>'})
tokenizer.pad_token = '<|pad|>'
print(tokenizer.pad_token_id)
print(tokenizer.eos_token_id)
model.resize_token_embeddings(len(tokenizer))
peft_model=PeftModel.from_pretrained(model,'genshin-impact-role-model-7B')
merged_model=peft_model.merge_and_unload()
merged_model.save_pretrained('genshin-impact-role-model-7B-merged')
tokenizer.save_pretrained('genshin-impact-role-model-7B-merged')
推理
message='砂糖来自哪个国家'
chat=[{"role":"user","content":message}]
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
check_point='genshin-impact-role-model-7B-merged'
tokenizer = AutoTokenizer.from_pretrained(check_point)
model = AutoModelForCausalLM.from_pretrained(check_point,torch_dtype=torch.float16, device_map="cuda")
model.to("cuda")
prompt=tokenizer.apply_chat_template(chat,tokenize=True,add_generation_prompt=True,return_tensors='pt')
print(tokenizer.chat_template)
prompt=prompt.to(model.device)
output=model.generate(prompt,
temperature=0.1,
top_p=0.1,
top_k=10,
max_length=512,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
) # 提前停止生成,防止不必要的输出)
print(tokenizer.decode(output[0],skip_special_tokens=True))
输出
砂糖来自蒙德
评估
from transformers import AutoTokenizer,AutoModelForCausalLM
import torch
model_name='maxwell60701/genshin-impact-role-chat-model'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16)
from datasets import load_dataset
raw_datasets=load_dataset('maxwell60701/genshin-impact-role-chat-model')
raw_datasets
我采用bertscore来进行评估,它支持中文
from evaluate import load
bertscore = load("bertscore")
import pandas as pd
# 定义方法写入csv
def write_to_csv(question, answer, prediction, precision,recall,f1,hash):
data = {'question': [question], 'answer': [answer], 'prediction': [prediction], 'precision': [precision],'recall':[recall],'f1':[f1],'hash':[hash]}
df = pd.DataFrame(data)
df.to_csv('evalute.csv', mode='a', header=False, index=False)
for item in raw_datasets['train']:
message=[item["messages"][0]]
question=item["messages"][0]['content']
answer=item["messages"][1]['content']
print(question)
print(answer)
prompt=tokenizer.apply_chat_template(message,tokenize=True,add_generation_prompt=True,return_tensors="pt")
prompt=prompt.to(model.device)
output=model.generate(prompt,
temperature=0.1,
top_p=0.1,
top_k=10,
max_new_tokens=512,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id)
response=tokenizer.decode(output[0], skip_special_tokens=True)
if "</think>" in response:
prediction = response.split("</think>")[-1].strip()
elif "<think>" in response:
prediction = response.split("<think>")[-1].strip()
else:
prediction = response.strip()
print(prediction)
predictions = [prediction]
references = [answer]
# 比较预期值和实际值得到分数
results = bertscore.compute(predictions=predictions, references=references, lang="zh", model_type="bert-base-chinese")
print(results)
precision=results['precision'][0]
recall=results['recall'][0]
f1=results['f1'][0]
hash=results['hashcode']
print(results['precision'][0])
write_to_csv(question, answer, prediction, precision,recall,f1,hash)
for item in raw_datasets['test']:
message=[item["messages"][0]]
question=item["messages"][0]['content']
answer=item["messages"][1]['content']
print(question)
print(answer)
prompt=tokenizer.apply_chat_template(message,tokenize=True,add_generation_prompt=True,return_tensors="pt")
prompt=prompt.to(model.device)
output=model.generate(prompt,
temperature=0.1,
top_p=0.1,
top_k=10,
max_new_tokens=512,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id)
response=tokenizer.decode(output[0], skip_special_tokens=True)
if "</think>" in response:
prediction = response.split("</think>")[-1].strip()
elif "<think>" in response:
prediction = response.split("<think>")[-1].strip()
else:
prediction = response.strip()
print(prediction)
predictions = [prediction]
references = [answer]
results = bertscore.compute(predictions=predictions, references=references, lang="zh", model_type="bert-base-chinese")
print(results)
precision=results['precision'][0]
recall=results['recall'][0]
f1=results['f1'][0]
hash=results['hashcode']
print(results['precision'][0])
write_to_csv(question, answer, prediction, precision,recall,f1,hash)
以上代码大致含义是将正确的答案,与模型推理的答案,进行比较打分
bertscore有三个指标
precision(精确率):生成答案中有多少内容与参考答案(标准答案)语义相符。衡量生成内容的“准确性”。
recall(召回率):参考答案中有多少内容被生成答案语义覆盖。衡量生成内容的“全面性”。
f1:精确率和召回率的调和平均值,是综合评价生成内容和参考答案语义相似度的指标。
可以用f1作为最终的评估指标
经过筛选,总数5100条,114条数据f1分数小于0.6